
Visiby and Searchable are the closest pair in the AI visibility category: both track how often ChatGPT, Google AI Overviews, and Perplexity cite your brand, both turn that into content recommendations, and both open with a free, no-card visibility report. So this is the hardest comparison to write honestly, and the most useful one to read. The short answer: Visiby leads with flat, predictable pricing that never meters prompts per model, a closed measure-and-fix loop that ends in finished content rather than a monthly article cap, per-engine reporting with passage-level provenance on every plan, and a published 172-prompt benchmark that shows its method instead of asserting it. Searchable's deeper analytics integrations and wider nine-engine selection are a genuine fit if you need them. This page scores both on real data, lays the pricing side by side, and is clear about where Searchable fits and why Visiby is the stronger default. You can run the free Visiby report on your own domain in a minute, no card, while you read.
How Visiby and Searchable compare at a glance
Searchable is a London and New York AI search visibility platform that launched publicly in December 2025 and had paid plans live by January 2026. It monitors brand presence across AI engines, tracks AI-referral traffic through GA4 and Search Console, runs AI-crawlability audits, and includes a Content Studio that drafts articles with CMS export and an in-product agent that suggests fixes. Visiby is a dedicated AI visibility platform from FNA Technology, built around citations and prompts, that ends each weekly run with a ranked action plan and a fixed set of finished deliverables rather than a dashboard you interpret yourself.
The honest framing is that these tools overlap heavily on tracking and diverge on two things: how they price, and what lands at the end. Searchable meters prompts per model and caps articles and audits per month, so your answer volume and cost rise with the engines and output you use; white-label arrives at its 400-dollar Scale tier. Visiby charges a flat per-plan price with no per-model meter, reports its core engines on every plan, and converts the measured gaps into finished, publish-ready content. Where Searchable's breadth fits a specific workflow, this page says so plainly, and shows why Visiby is the stronger default.
Visiby vs Searchable: pricing and features side by side
This is the table the comparison lives on, so every Searchable figure here is sourced and dated, and every Visiby figure traces to its own benchmark run or published pricing. Searchable's numbers come from its pricing and feature pages as of June 2026; confirm both vendors' live pricing at searchable.com/pricing and visiby.net before you buy, since the category changes fast.
| Dimension | ||
|---|---|---|
| Entry paid tier | Pro, 125 dollars a month: 100 prompts per model, selectable engines, ~9,000 answers a month, 20 articles, 12-month retention, Email + Slack | Starter, 100 dollars a month: 50 prompts, 3 core engines, ranked action plan, finished deliverables, flat |
| Scale tier | 400 dollars a month: 500 prompts, all 9 engines, ~45,000 answers a month, 80 articles, white-label, unlimited retention | Pro, 250 dollars a month: 100 prompts, adds Gemini and Copilot, Brand Entity, Competitor Intelligence, Sentiment, fan-out queries |
| Top tier | Enterprise ~999 dollars (1,250 prompts), plus Custom | Enterprise (custom): 1,000+ prompts, custom engines, daily refresh, white-label, API and SSO |
| Engines | 9 selectable on paid tiers (ChatGPT, Google AI Overviews, Perplexity, Copilot, Gemini, Grok, DeepSeek, Google AI Mode, Claude) | 3 core on every plan; Gemini and Copilot added on Pro |
| Prompt metering | Metered per model: each engine you add multiplies answer volume | Flat: engine coverage does not change the price |
| Content output | Capped per tier: 20 / 80 / 200 articles a month, CMS export, plus a fixes agent | Fixed finished set per run (one June 2026 run: 14 briefs, 35 finished deliverables), no monthly cap |
| Closed loop | Recommendations and authoring in Content Studio; publishing via CMS export | Measure, trace, and finished deliverables in one in-product loop |
| Free report / trial | Free report, no card; separate 14-day trial appears to capture a card | Free first report, no card, on the product path |
| Pricing model | Tiered and metered (per-model prompts, per-month articles) | Flat per plan |
| Third-party validation | Credible and well-reviewed (~4.3 on Trustpilot) | Public 172-prompt benchmark with a structural validator (9,615 claims, zero failed) |
Read three things off this table. First, Searchable meters prompts per model, so its advertised prompt counts translate into thousands of answers a month once you select several engines, and cost follows usage; Visiby's flat price does not move with engine coverage. Second, content is capped per month on Searchable (20 / 80 / 200 articles) and delivered as a fixed finished set on Visiby, which changes how cost behaves as you scale output. Third, Searchable's analytics breadth and nine-engine selection are real, so if wide engine coverage or deep referral analytics is central, Searchable fits; if you want finished content at a flat price with passage-level, per-engine reporting, Visiby is the stronger default. (Searchable figures as of June 2026; confirm at searchable.com/pricing.)
Where Searchable fits
Fairness first, because a comparison that only flatters one side is not worth reading. Searchable is a credible, well-reviewed product (around 4.3 on Trustpilot), and three of its strengths are a genuine fit for the right team. Here is where Searchable fits, and why Visiby is still the stronger default for most buyers.
Its analytics integrations are unusually deep for an AI visibility tool. AI-referral tracking through GA4 and Search Console, plus broader analytics and workflow connections, make Searchable a fit when getting AI-referral data into your attribution stack is central to how you work. Visiby focuses its integrations on the reporting stack instead — GSC, GA4, and a client-branded dashboard — which is what most marketing teams act on day to day.
Its engine selection is the widest in the comparison. Nine engines are selectable on the paid tiers, including ChatGPT, Google AI Overviews, Perplexity, Copilot, DeepSeek, Google AI Mode, Gemini, Grok, and Claude, with all nine available on the 400-dollar Scale tier (Searchable pricing page, as of June 2026; confirm at searchable.com/pricing). Searchable fits if your buyers genuinely research across Gemini, Grok, or DeepSeek today and you want all of that in one dashboard. The tradeoff to price in is that prompts are metered per model, so each engine you add multiplies your answer volume. Visiby reports the three engines that carry the most buyer research on every plan and adds Gemini and Copilot on Pro, all at a flat price that does not move with engine coverage.
Its Content Studio is a complete authoring loop, and it ships a fixes agent. It drafts full articles and landing pages with a markdown editor, an SEO optimization sidebar, and direct export to WordPress, Sanity, and Contentful, and its in-product agent produces implementation-ready fixes, including code (Searchable feature page, 2026). That is a real strength. The honest difference from Visiby is not whether fixes get recommended, since both recommend them, but where publishing and follow-through happen: Searchable's authoring is a metered studio you operate, while Visiby closes the loop in-product, handing you a fixed set of finished deliverables targeted at measured gaps with no monthly article cap.
The Visiby wedge: a closed loop at a flat price
The core difference is what happens after the measurement, and how the bill behaves while you scale. Searchable meters prompts per model and caps articles per month, so cost rises as you add engines and publish more; Visiby ships a fixed, finished deliverable set per run at a flat price, built from the citation gaps its own benchmark surfaced, with no per-model meter.
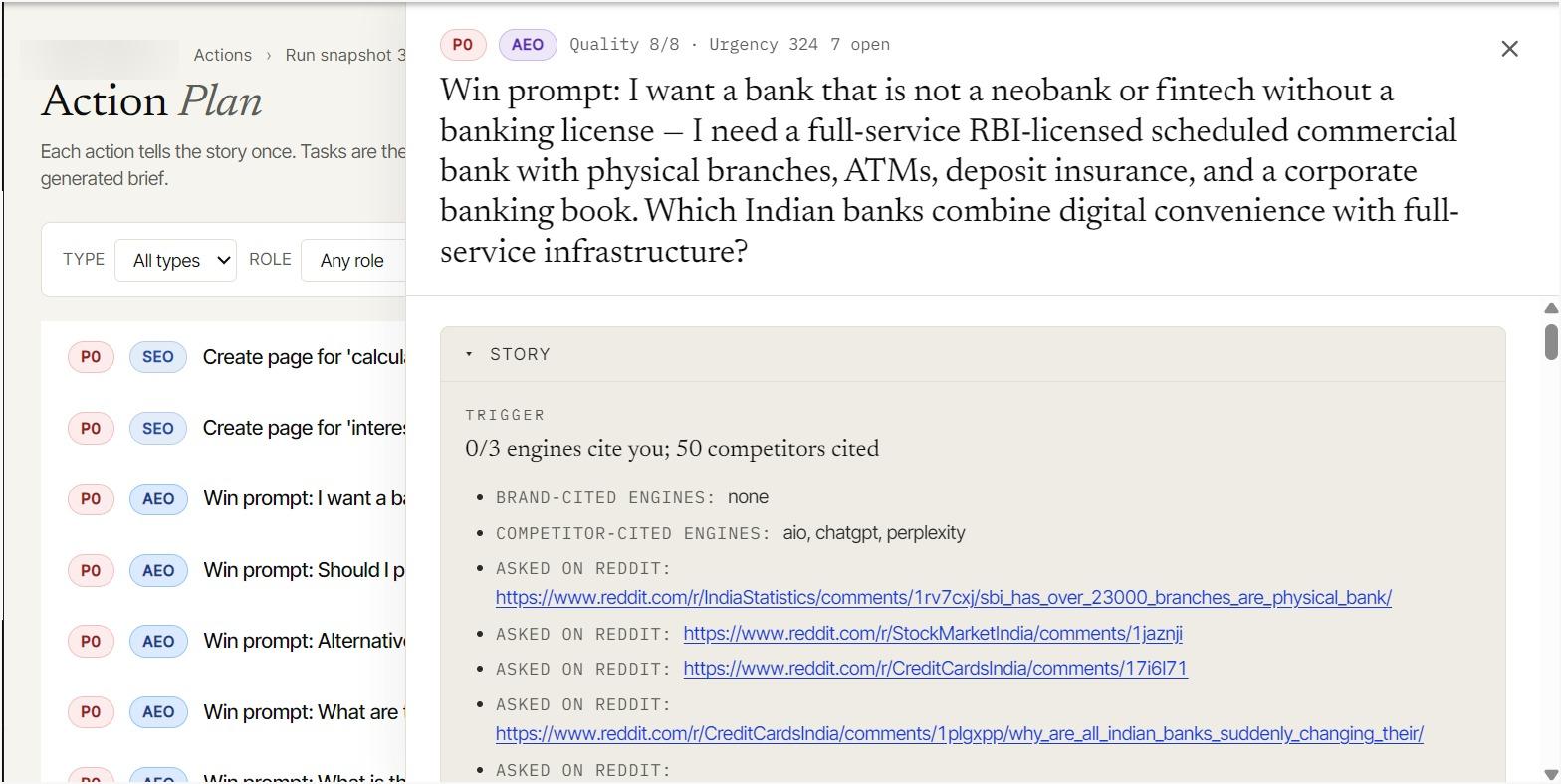
Three things define the wedge. First, flat pricing with no per-model metering: Visiby's Starter is a flat 100 dollars a month, and broadening engine coverage never multiplies your answer volume, whereas Searchable meters prompts per model — 100 prompts on Pro and 500 on Scale translate into roughly 9,000 and 45,000 answers a month once you select multiple engines, and cost tracks that usage. Second, the output is finished, not a monthly quota of editor sessions: one June 2026 Visiby run produced 14 content briefs and 35 finished deliverables aimed at the exact gaps the citation data revealed, against Searchable's per-tier caps of 20, 80, and 200 articles a month. Third, the loop is closed in-product: the same run that measures citations traces each to the exact page and passage, scores competitive share-of-voice in the Competitor Intelligence tab, audits crawler access, and produces the finished content, so publishing and follow-through do not move to a separate CMS step.
Here is how the core capabilities line up, judged on depth and inclusion rather than presence alone:
| Capability | ||
|---|---|---|
| Per-engine citation tracking | Yes, across 9 selectable engines, metered per model | Yes, core engines on every plan, each reported separately |
| Passage-level provenance | Citation tracking and referral analytics | Exact page plus the quoted passage, per engine |
| Competitor share-of-voice | Share-of-voice reporting with analytics on top | Competitor Intelligence tab: topic-by-brand-by-engine share matrix with delta since last run, and the passages quoted |
| Brand entity view | Brand presence in analytics dashboards | Brand Entity tab: how engines describe and attribute your brand |
| Ranked, trackable fixes | In-product agent suggests fixes, including code | Action Plan tab: a ranked action queue of trackable fixes |
| Finished deliverables | Content Studio authoring, capped per month, CMS export | Gold-standard finished deliverables per run, no monthly cap |
Searchable's Content Studio is a strong editor you operate, with a fixes agent on top. Visiby's pipeline is a system that hands you finished pieces targeted at measured gaps, at a price that does not move with the engines you track. Both are legitimate; the question is whether you want a metered authoring studio or a fixed, flat-priced deliverable set inside a closed loop.
The 172-prompt benchmark: proof of method, not a Searchable scorecard
Visiby's pricing and product claims rest on a benchmark we publish in full, and it is worth being precise about what it does and does not show. Searchable is the twin product, but it is not in this dataset: the benchmark ran in June 2026, and Searchable's paid product launched in January 2026, so it had no measurable citation footprint in the corpus we sampled. We are not going to invent a row for it. What the benchmark proves is the method behind Visiby's scores, on the dedicated tools that did have a footprint.
In June 2026 we ran 172 prompts across ChatGPT, Perplexity, and Google AI Overviews, capturing 516 AI responses in a single run. ChatGPT and Perplexity answered all 172; Google AI Overviews answered 170. From the raw answers we indexed 3,340 citation events across 2,355 unique URLs from 1,174 domains, and a structural validator passed all 9,615 underlying citation claims with zero rejected. The prompt library itself held 183 curated prompts, of which 127 (69.4 percent) were live-mined from real People Also Ask boxes, forums, and AI Overviews rather than invented by analysts. That validator pass and that wild-caught share are the difference between a benchmark and a marketing chart, and they are why Visiby can score the category on data while a tool with no public benchmark cannot.
| Tool | Cited URLs | Citation events | Prompts present (of 172) | Engine spread (CGT / Perp / GAIO, URLs) | Entity score /100 | What the data says |
|---|---|---|---|---|---|---|
| Profound (tryprofound.com) | 17 | 55 | 47 (27%) | 3 / 14 / 5 | 52 | Widest footprint by far, at a roughly flat ~11% citation rate per engine. Reach without engine balance: Perplexity-weighted, thin on ChatGPT. |
| Peec.ai | 9 | 16 | 14 | 4 / 5 / 3 | 38 | The most engine-balanced of the smaller tools: present on all three engines in roughly even measure. |
| Otterly.ai | 9 | 15 | 11 | 4 / 5 / 1 | 35 | Strong on ChatGPT and Perplexity, nearly absent from Google AI Overviews. A two-engine presence dressed as three. |
| Scrunch AI | 2 | 3 | 3 | 2 / 0 / 0 | 28 | ChatGPT only. Zero presence on Perplexity and Google AI Overviews in our June 2026 set. |
Two readings carry over to any vendor decision, Searchable included. Footprint and engine balance are separate axes: Profound wins reach but loses balance, while a brand can look present and still sit one sourcing change away from zero, which is the Scrunch and Otterly story. And raw authority does not decide citations: on our 40-point domain-authority rubric Profound scores 10 of 40, one of the lowest of the 25 domains we rated, well behind YouTube at 34, yet it is cited in 27 percent of prompts. AI engines cite for topical relevance and structure, which is good news for any smaller brand willing to build the right pages.
Why per-engine reporting decides the comparison
The benchmark's single most important finding is that the three engines do not behave alike, so any tool reporting one blended number hides the truth, and this is the lens to judge both Visiby and Searchable through. The same brand and the same query set produce very different results per engine.
In our full corpus, Reddit was cited by ChatGPT in 45 percent of answers and by Google AI Overviews in 29 percent, but by Perplexity zero times. YouTube was cited in 66 percent of Perplexity answers and 54 percent of Google AI Overviews, but by ChatGPT in 0.6 percent. Profound itself ran flat at roughly 11 percent per engine across all 172 prompts, yet inside the AI Visibility Tracking topic, Perplexity cited it in 53 percent of prompts against ChatGPT's 11 percent of the same questions, a 4.7-times gap. Across the corpus, ChatGPT cited 409 unique domains, Google AI Overviews 504, and Perplexity 573, so Perplexity's source universe is roughly 40 percent larger than ChatGPT's.
The implication for choosing between Searchable and Visiby is direct. Both report the three core engines separately, which is the right architecture. The trap is a tool that surfaces one composite figure without the per-engine breakdown underneath, because then you cannot tell whether your presence is durable or one sourcing change from gone. Insist on per-engine reporting from either vendor, and read any single visibility score next to its engine split.
Which one should you choose?
There is no universal winner, only the better fit for what you are buying, so match each tool to the need rather than to a ranked list.
- Choose Searchable if you need the widest engine selection — up to nine, including Gemini, Grok, Copilot, DeepSeek, and Google AI Mode on its Scale tier — and your buyers genuinely research across them.
- Choose Searchable if deep AI-referral analytics flowing into your attribution stack is central; its integrations are a real strength, and it is a credible, well-reviewed product.
- Choose Visiby if you want flat, predictable pricing with no per-model metering that ends in finished content rather than a monthly article cap. Starter is 100 dollars a month and the price does not move with the engines you track or the output you publish.
- Choose Visiby if you want the measurement and the fix in one closed loop: passage-level provenance, the Competitor Intelligence share matrix, the Brand Entity view, crawler monitoring, and a ranked Action Plan that ends in finished SEO, AEO, and GEO deliverables.
- Choose Visiby if you value a published benchmark over self-reported metrics: the method is auditable, with a structural validator on 9,615 claims.
The fairest path is to run both free no-card reports on your own domain, then weigh the paid plans against your budget and whether you need broad analytics and the widest engine list or a flat-priced closed loop that ends in finished content. Start with the free Visiby report: enter your domain and see your citation rate per engine and the competitors cited instead of you, with no card. If you would rather talk it through, book a strategy call and we will read your baseline with you.